Helpdesk IBM SPSS Statistics 20 Helpdesk IBM SPSS Statistics 20For students from Arnhem Business School | ||||||||
| Home | Codebook | Data | Data editing | Analysis | Graphs | Settings | Links | Methods |
|
Helpdesk IBM SPSS Statistics 20 For students from Arnhem Business School | ||||||||
| Home | Codebook | Data | Data editing | Analysis | Graphs | Settings | Links | Methods |
Data Merge filesUsing Merge Files you can combine two data files. There are two ways of doing this, namely:
Add CasesWe show the process distinguishing three steps:
The preparationWhen a project group uses face to face interviews - for example during a fair
- or a written questionnaire the data entry has to be done manually. In such a
case it is convenient if several people work on this parallel to each other.
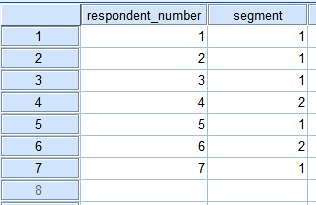
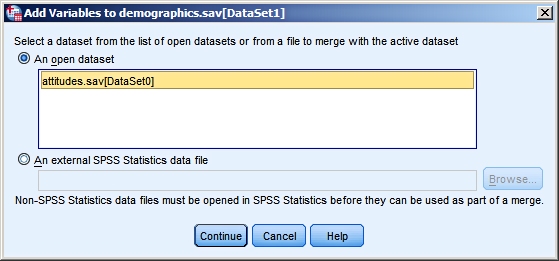
The merging in SPSSIn this example we use three separate data files: merge_files_1.sav, merge_files_2.sav and merge_files_3.sav. If you open merge_files_1.sav in SPSS, you will see that it contains 7 cases.
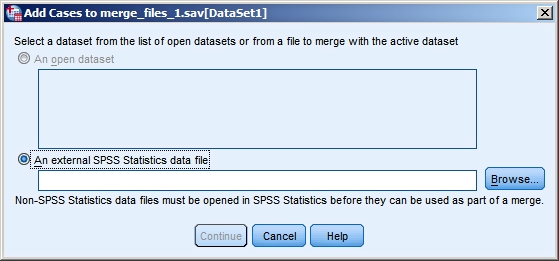
The following dialog box opens:
Browse to merge_files_2.sav and click Continue. Note: An alternative is to open merge_files_2.sav first;
then the file will be listed under "An open dataset".
The Result
|
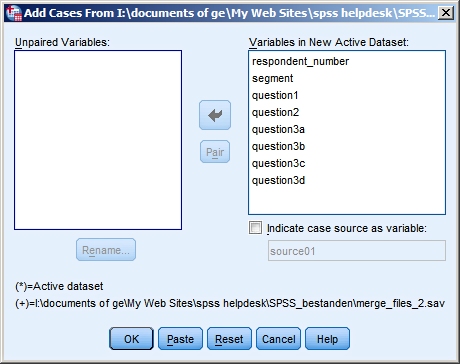 |
We can infer from it that:
|
Now click OK. Part of the data windows now looks as follows:
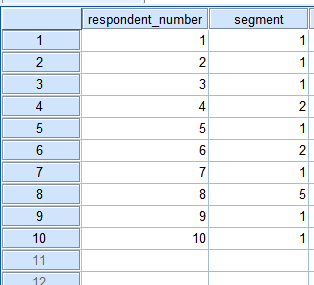 |
We see the data file now contains new cases next to the original 7 from merge_files_1.sav. Since we used the identification variable respondent_number it is easy to check whether the merging process was successful and all the questionnaires involved are in the merged file. |
It is now up to you to merge merge_files_3.sav to
the active data file.
Save the end result under a proper name. We used
merge_files_total.sav.
![]()
In our example we have a data file with basic information about our
customers, containing demographics, characteristics, self-declared info and the
like. This data is collected in the SPSS file
demographics.sav.
For a number of our custumers we have additional attitudinal data. It is in the
SPSS file attitudes.sav.
Below you can see the two data files. Every customer has a unique identification code (variable number) and both files contain additional information.
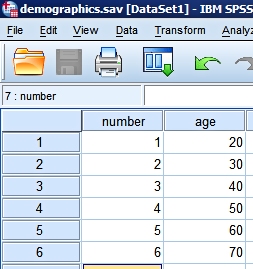 We know how old each customer is (variable age). |
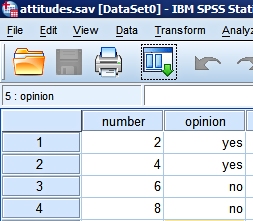 We asked some people "Do you like Brussels sproutes?". So we know some of their preferences (variable opinion). |
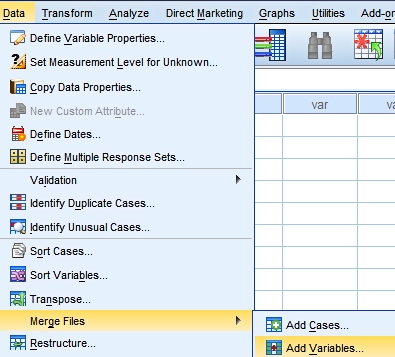
We want to combine this into one merged file. We start by opening the file demographics.sav and we choose from the menu Data > Merge Files > Add Variables.
 |
|
Of course we want to add the extra info about the liking of Brussels sproutes
correctly to each of the customers. For this we use a key variable (in our
example it is called number).
This provides a unique identification for each customer. Through this variable
we are able to add the opinion variable to our file with basic info.
It is essential that both files in the addition process are sorted in ascending order on the key variable, before the merging starts.
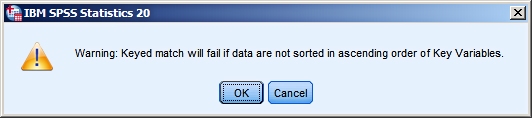
As the screendumps above show you we have taken care of this. So we may continue to the next step and specify the merging.
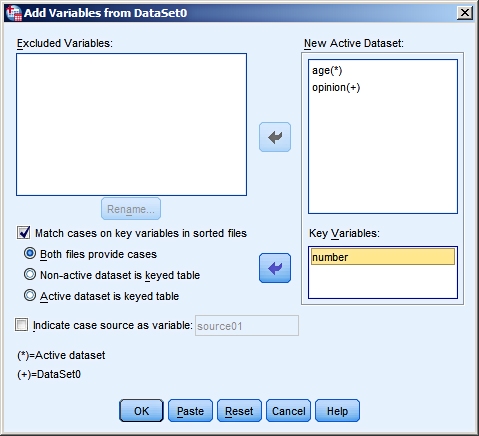 |
As you can see we have
indicated we want to "match cases on key variable in
sorted files". And "both files provides cases". |
Everything is set. Click OK to see the result:
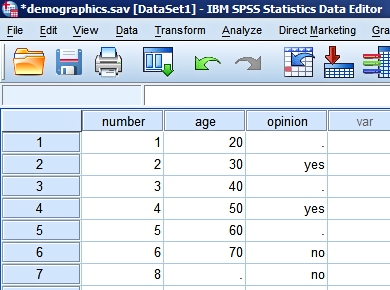 |
The data view after the
merging shows what has happened. |
![]()
Last modified
30-10-2012
 © Jos Seegers, 2009; English version by Gé Groenewegen. |